
Buffer overflow & consort : tout ce que vous devez savoir
De nombreuses vulnérabilités dans les systèmes informatiques sont liées à des erreurs de gestion de la mémoire, permises entre autres par l'utilisation de langages de bas-niveau répandus tels que le C et le C++. En 2019, elles constituaient pour Microsoft environ 70% des vulnérabilités traitées.


Introduction
Cet article vise tout public qui cherche à comprendre ces familles de vulnérabilités liées à la gestion de la mémoire et qui sont non seulement communes, mais aussi très dangereuses. Il est conseillé néanmoins d'avoir quelques bases pour mieux suivre, mais le public visé est large.
Dans un premier temps, nous chercherons à définir ces vulnérabilités. Ensuite, nous verrons ce que les développeurs peuvent faire à leur niveau pour les éviter. Enfin, nous insisterons sur quelques mesures de protection mises en place sur des systèmes modernes.
Constat
Je suis tombé il y a quelques mois sur cet article très intéressant d'un développeur de curl, un projet qui fournit des bibliothèques et des outils CLI que nous connaissons bien et que nous utilisons au quotidien. Pour la faire courte, ce développeur a compté que sur 98 vulnérabilités reportées, 51 d'entre elles soit 52% étaient dues à des erreurs de la gestion de la mémoire avec C.
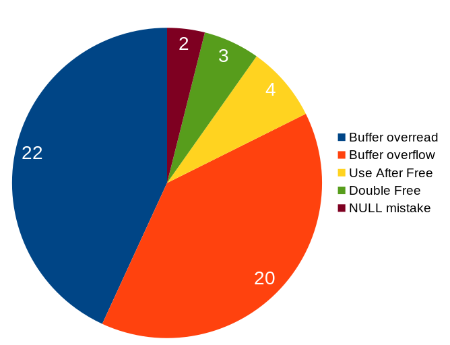
Ces vulnérabilités sont non seulement répandues, mais elles ne sont pas plus évidentes à détecter que les autres : en moyenne pour curl, une vulnérabilité du genre est présente pendant 2412 jours dans le code soit à peine moins (relativement) que des vulnérabilités plus exotiques.
Ce n'est bien sûr pas une tendance propre à curl qui est un simple exemple. De nombreux programmes sont écrits depuis des décennies en C/C++ et sont toujours utilisés aujourd'hui.
Regardons maintenant du côté de Chromium :
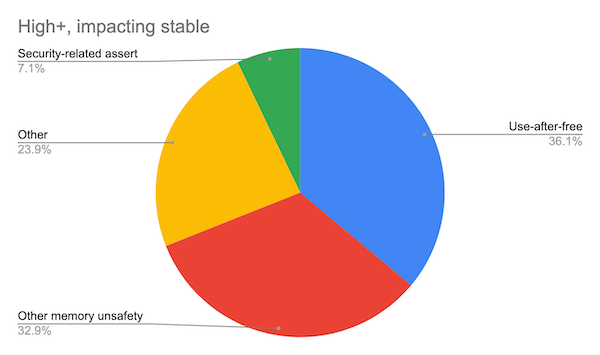
Même histoire : la majorité des vulnérabilités de haute sévérité (ou plus) sont liées à des problèmes de mémoire, qui auraient pu être évités...
En fait, de très nombreuses (si ce n'est la totalité) codebases sont impactées par ce problème : Linux, Windows, Chromium, Firefox, et il y a quelques jours macOS et iOS (WebKit). Ce ne sont que des exemples qui montrent bien que personne n'est infaillible, pas même des projets aussi importants. Il faut également tenir compte des dépendances multiples qui ont leurs propres vulnérabilités du genre... En 2014, c'est tout Internet qui trembla avec Heartbleed, une faille dans l'extension Heartbeat d'OpenSSL.
Plus généralement, une étude de 2019 faite par Microsoft indique qu'environ 70% des vulnérabilités observées chaque année sont liées à des problèmes de sûreté de la mémoire.
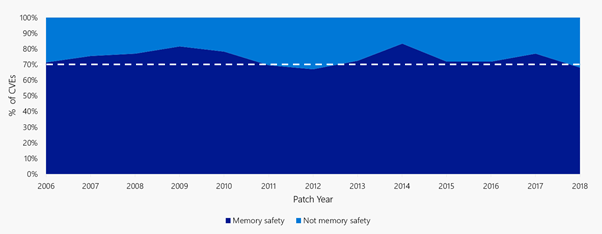
Ces vulnérabilités peuvent évoquer la célèbre figure de l'épée de Damoclès. Elles sont parfois déjà exploitées dans la nature avant même qu'elles ne soient portées à la connaissance des développeurs responsables. Fort heureusement, je souhaite tempérer cette situation catastrophique : il existe des mécanismes de protection contre ces 0-day buffer overflow.
Les vulnérabilités liées à la gestion de la mémoire
Je propose que nous effleurions ensemble plusieurs types de ces vulnérabilités. Il y a beaucoup de subtilités qui ne seront pas abordées ici, ce billet cherchant à être concis et accessible. J'apprécie distinguer 2 types de vulnérabilités liées à la mémoire :
- Spatiales (buffer overflow, over-read)
- Temporelles (use after free)
L'objectif de cette partie sera de comprendre le sens de cette distinction, et comprendre de surface comment ces vulnérabilités fonctionnent et peuvent être exploitées par un attaquant !
Buffer overflow
C'est sans doute la famille de vulnérabilités dont vous entendez le plus souvent parler. Buffer overflow se traduit littéralement en français par dépassement de la mémoire tampon.
Le buffer est un endroit de la mémoire (la RAM typiquement) qui est alloué pour stocker temporairement des données d'une certaine taille. Si le programme qui se voit allouer le buffer envoie plus de données qu'il n'était prévu, il y a le risque que le programme puisse altérer et corrompre des régions adjacentes au buffer dans ladite mémoire : ce qui peut avoir des conséquences catastrophiques.

Ce mécanisme peut en effet être exploité par un attaquant pour modifier ces régions adjacentes qui peuvent contenir des pointeurs (des références à d'autres endroits de la mémoire), pour les remplacer par d'autres pointeurs vers du code malveillant. Le programme est ainsi compromis : l'attaquant peut dans le pire des cas gagner en privilèges sur votre machine.
En C par exemple, l'usage de strcpy (copie d'un string) peut mener à cette situation assez facilement (code simplifié) :
void foo(char *str)
{
char buffer[5];
strcpy(buffer, str); // Situation d'overflow !
}
int main()
{
char *str = "Hello overflow"; // Plus que 5 bytes !
foo(str);
return 1;
}C'est pour cela qu'il vaudrait mieux dans cet exemple utiliser strlcpy qui permet de définir la taille maximum de ce que l'on prend, idéalement sizeof(buffer) pour ne prendre que la taille maximum du buffer et absolument rien d'autre. Il faut éviter les fonctions unsafe !
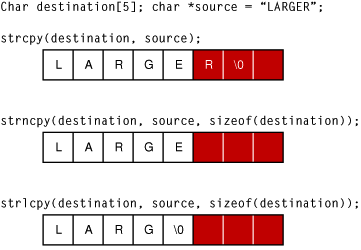
Ici, ce code est gentil et ne sait pas trop ce qu'il fait, c'est ce qu'un programmeur novice en C pourrait écrire. Mais soyez sûr que ce genre d'erreur arrive à une échelle bien plus complexe, avec des inputs rentrés par un utilisateur pour exploiter la mauvaise conception du programme. Un attaquant pourrait tout à fait ainsi faire exécuter du code malveillant en contrôlant cette situation d'overflow.
Différentes sources d'erreurs peuvent être à l'origine de buffer overflows : mauvaise gestion des strings, unicode, integer overflow, etc.
Il existe en réalité deux grands types de buffer overflow car il y a deux modèles principaux d'allocation dans la mémoire :
- Stack overflow : le même nom du célèbre site provient de ce terme ! La stack est un modèle d'allocation rapide qui fonctionne comme une pile : le dernier élément qui arrive est aussi celui qui est traité en premier (LIFO). La stack fonctionne en tandem avec des registres de pointeurs au niveau du CPU, sans rentrer dans les détails.
- Heap overflow : heap peut se traduire par tas, c'est un modèle d'allocation moins rapide et désorganisé de mémoire, mais adapté quand la manipulation doit être gérée de façon explicite ou implique de gros morceaux de données.
Par exemple, la CVE-2021-3156 est une vulnérabilité de type heap overflow qui concernait sudo. Ces différences ont des implications en termes de complexité d'exploitation et de protection.
Buffer over-read
Là où les buffer overflow (aussi appelées buffer over-run) permettaient d'écrire directement dans des mémoires adjacentes au buffer, les buffer over-read permettes de lire des endroits parfois critiques de la mémoire qui ne sont pas censés être accessibles.
Ces vulnérabilités sont classiques dans des opérations de lecture, mais elles peuvent avoir des conséquences néfastes pour la sécurité du programme : Heartbleed en fut un triste exemple en 2014.
Use after free
Les vulnérabilités use after free exploitent des pointeurs qui référencent un endroit de la mémoire qui ne contient plus l'objet supposé être contenu dans cet espace : ces pointeurs sont appelés dangling pointers (ou encore pointeurs sauvages).
Un exemple très simple en C++ :
// explicite
int *ptr = new int;
*ptr = 3;
int *ptr2 = new int;
*ptr2 = 5;
// explicite
ptr = ptr2;
// on désalloue ptr2
delete ptr2;
ptr2 = nullptr;
// ptr est désormais un dangling pointer !Ce code qui fait un peu n'importe quoi crée deux pointeurs qui référencent des entiers. Puis on décide finalement que le premier pointeur pointera vers le même espace de la mémoire que le deuxième. Enfin, on utilise delete pour désallouer la mémoire correspondante au second pointeur : le premier pointeur ne pointe plus vers un espace de la mémoire valide.
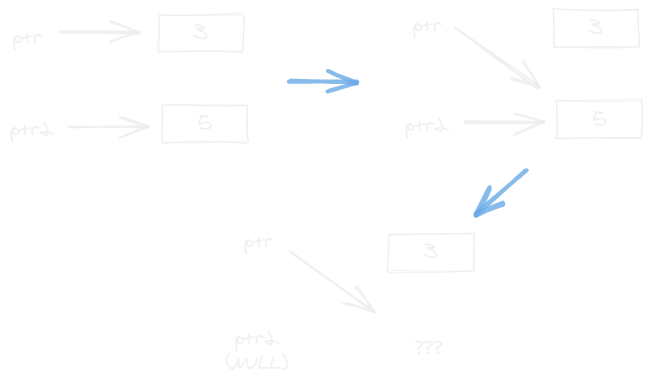
Bien qu'il existe des mécanismes de protection au niveau du système que nous verrons par la suite, un développeur en C/C++ est par exemple tenu de faire très attention à l'existence de ces dangling pointers.
Un exemple ? checkm8 qui exploite une vulnérabilité use after free dans le code lié à la gestion USB dans la Boot ROM des iDevices.
Erreurs liées à NULL
C'est une erreur de sûreté de typage plutôt que de la gestion de la mémoire, mais les deux sont très souvent liés.
NULL est un concept de "valeur qui n'est pas une valeur" utilisé dans différents paradigmes et langages de programmation : Python (None), Ruby (nil), JavaScript/autres (null), etc.
Si vous avez déjà programmé dans un de ces langages, vous savez très bien l'utilité de ce concept : il sert par exemple à représenter l'absence d'une valeur, ce qui est indéniablement utile dans certaines situations.
Cependant Tony Hoare, inventeur du concept dans les années 60, ne l'appelle pas the billion dollar mistake pour rien :
I call it my billion-dollar mistake. It was the invention of the null reference in 1965. [...] This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
C'est sans doute sensationnaliste, mais ce n'est pas sans raisons non plus ! Par le "coût", il veut dire par les bugs que cette conception peut provoquer dans un programme : au mieux un crash, au pire une vulnérabilité critique. Les différents langages héritent de différents problèmes à différents degrés de complexité liés à leur utilisation de NULL.
Le problème concernant des langages de bas-niveau comme C, c'est par exemple le déréférencement de pointeurs NULL :
int a, b, c; // quelques entiers
int *ptr; // pointeur ptr
a = 5;
ptr = &a; // ptr -> a (0x...)
b = *ptr; // b = 5
ptr = NULL; // ptr -> NULL (0x000000 ou autre)
c = *ptr; // ???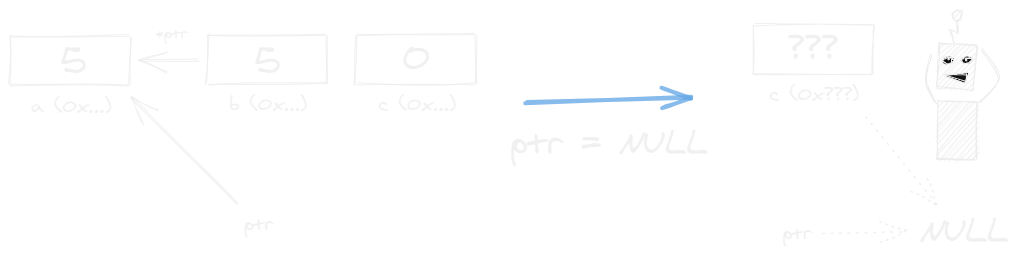
Un pointeur vers NULL est censé être un pointeur invalide, vers un espace de mémoire inexistant. Seulement chaque plateforme peut avoir sa définition de ceci. Son déréférencement est erroné : c'est une opération invalide qui mène à un comportement indéfini plateforme-dépendant :
- La plupart du temps, le système bloque cette tentative d'accès à une mémoire invalide (segmentation fault / memory access violation).
- Parfois, ce n'est pas le cas dans certains environnements, et cela peut avoir des conséquences sur l'intégrité du système et donc sa sécurité.
Double free
La vulnérabilité double free est un peu moins connue, mais toujours une menace à ne pas oublier : par exemple la CVE-2016-0705 chez OpenSSL (dans le cadre du parsing de clés DSA).
char* ptr = (char*)malloc (SIZE);
...
if (abrt) {
free(ptr);
}
...
free(ptr);C'est un exemple simple mais servant à illustrer la confusion qui est la première cause à l'origine de ce type de vulnérabilité : quelle partie de code est responsable de libérer la mémoire (free()) ? Plus un code se complexifie, plus il est difficile de debug ces problèmes.
Le programme C en question appelle free() potentiellement deux fois avec le même argument, ce qui peut avoir pour conséquence de corrompre la gestion de la mémoire du programme, avec au mieux un crash. Cependant, il est possible dans certaines circonstances de manipuler le programme pour que ce dernier devienne ainsi vulnérable à une buffer overflow.
Situation de compétition
Appelée race condition en anglais, c'est un problème qui peut toucher plus ou moins n'importe quelle architecture, et n'importe quel programme écrit dans n'importe quel langage ; si bien que nous n'allons pas nous attarder dessus.
Une situation de compétition est une situation de concurrence dans laquelle des données sont réparties entre plusieurs tâches. Si des précautions ne sont pas prévues, cette situation peut être exploitée par un attaquant qui pourra mener des attaques de déni de service (DoS) avec élévation de privilèges dans le pire des cas.
Peut-être que l'on en parlera un autre jour plus en détails...
Au niveau du programme : comment les éviter ?
Ces vulnérabilités sont loin d'être rares, en conséquence il existe de nombreux mécanismes de protection sur les OS et compilateurs modernes pour y faire face, et au moins compliquer leur exploitation. Toutefois ces mécanismes ne sont pas parfaits, et dans beaucoup trop de situations l'exploitation demeure possible.
La première barrière de protection consiste simplement en l'écriture d'un programme avec le moins de bugs possible. Il existe différents moyens d'y parvenir, plus ou moins efficaces, et demandant plus ou moins d'efforts.
Langages memory-unsafe
Nous l'avons vu : ces langages sont typiquement le C et le C++. Ce sont des langages de bas-niveau qui permettent une gestion poussée de la mémoire à des fins d'optimisation, mais si cette gestion est chaotique elle peut mener à des bugs qui peuvent être très graves.
Tu peux faire ce que tu veux, tu n'as qu'à être assez attentif et expérimenté pour produire du code sûr.
Telle est la philosophie de ces langages :
- En théorie, il est tout à fait possible de produire du code en C/C++ qui soit totalement sûr (plus simple avec du C++ moderne).
- En pratique, c'est peu probable, chaque humain fait des erreurs qu'il le veuille ou non ! D'autant plus sur des bases de code complexes et énormes, et parfois vieillissantes.
Bien sûr, il n'est parfois pas concevable de les jeter simplement pour une alternative, car ce travail de portage ne serait justement pas simple du tout. C'est l'idéal, mais soyons pragmatiques…
Il faut donc adopter de bonnes pratiques telles que le recours général au bounds checking (massivement employé de façon intensive dans les langages de haut-niveau) et éviter des fonctions employées dangereusement, comme ci-dessus en C avec strcpy.
Le bounds checking (littéralement vérification de limites) permet d'éviter des buffer overflow classiques - car traditionnellement le C/C++ permettent d'écrire des données au-delà des limites d'un buffer.
Le C++ moderne propose par exemple divers moyens d'implémenter la pratique du bounds checking dans son code, via des conteneurs proposés par la Standards Template Library. Par exemple, considérez ce code :
void read_into(int* buffer, size_t buffer_size);Qui peut être réécrit en C++20 grâce à std::span ainsi :
void read_into(span<int> buffer);Concernant les vulnérabilités temporelles, le C++ permet également l'usage de smart pointers (pointeur intelligent en français) qui ont l'avantage d'éviter justement l'existence de dangling pointers :
void UseRawPointer()
{
// pointeur classique
Song* pSong = new Song(L"Resonance", L"HOME");
// ...
// On pense à supprimer le pointeur !
delete pSong;
}
void UseSmartPointer()
{
// On déclare un smart pointer (ici unique_ptr)
unique_ptr<Song> song2(new Song(L"Resonance", L"HOME"));
// ...
} // song2 sera automatiquement indisponible ici (out of scope!)Il est donc bon de rappeler que le C++ est un langage qui évolue et dont la dernière révision remonte à 2020 - alors que les problématiques liées à la mémoire prennent une proportion de plus importante. Les développeurs expérimentés en C++ ont tendance à utiliser ces outils qui leur permettent de produire un code plus sûr en premier lieu.
Outre les bonnes pratiques, il existe sans doute une pléthore d'outils qui permettent aux développeurs de détecter en amont ces problèmes :
- Valgrind (Memcheck)
- ASan (Address Sanitizer)
- MSan (Memory Sanitizer)
- KASAN (KernelAdressSAnitizer pour Linux)
- kmemcheck (pour Linux)
Bref, les experts en C/C++ sauront mieux que moi sur ce sujet.
Langages memory-safe
Ces langages sont surtout de haut-niveau (mais également de bas-niveau), et de différents paradigmes :
- Python
- Java
- JavaScript
- Go
- Haskell
- Kotlin
- Rust
- Etc.
Les langages de haut niveau implémentent souvent ce qu'on appelle un garbage collector : c'est ce mécanisme qui s'occupera de nettoyer la mémoire allouée qui n'est plus référencée et protège par nature de vulnérabilités comme les use after free sans que le développeur n'ait à y penser derrière. Le bounds checking est également de la partie, ce qui protège par nature ces langages des overflows.
Il faut donc se poser une question essentielle qui dépasse la question (déjà très importante) de la sûreté :
Quel langage est le plus adapté pour mon projet ?
Ce n'est pas pour rien que des langages comme Python existent et permettent une abstraction qui rend la programmation accessible et efficiente. C'est un langage adapté pour de nombreux outils, comme les autres langages de haut-niveau (qui ont chacun leur spécificité et compromis), où les performances ne sont pas forcément cruciales.
Mais ce n'est pas pour rien non plus si des langages comme C++ existent. Ce sont des langages qui permettent une optimisation fine de la mémoire, permettent de compiler du code natif très performant et économe. Ces langages de bas-niveau sont le candidat idéal pour de la programmation système et permettent de tout faire en théorie.
Choisir le langage adéquat est une étape importante, car là où vous n'avez pas besoin de performances, vous gagnez en abstraction et en productivité, mais aussi en sécurité.

Un langage s'est décidé à casser cette idée de compromis binaire : ce n'est autre que Rust. Après des décennies d'expériences à évaluer tout ce qui va et tout ce qui ne va pas dans les langages classiques de bas-niveau, Rust a été créé pour être un langage de bas-niveau moderne et sûr, et conservant la rapidité d'un langage de bas-niveau.
Tu peux faire ce que tu veux, mais je vais te pincer si tu fais une connerie. Donc tu es forcé de suivre mes règles !
Rust implémente la sûreté de différentes façons contre ces vulnérabilités spatiales et temporelles, notamment par un compilateur intransigeant (réputé aussi pour être un peu lent) :
- Rust est un langage typé fort : le compilateur doit pouvoir vérifier les types des variables au moment de la compilation.
- Rust n'a pas de type
NULLà proprement dit, mais pousse une alternative qui consiste à utiliser un type polymorphiqueOption<T>qui contientNoneouSome(T). - Rust ne permet pas l'existence de dangling pointers : chaque référence est suivie par le compilateur pour ne pas survivre (lifetimes) au-delà de la valeur à laquelle elle se réfère, évitant ainsi les use after free.
- Il n'est d'ailleurs pas possible d'avoir plus d'une référence mutable
&mut(mais on peut avoir plusieurs références immutables&). - Outre son modèle robuste de borrowing (emprunt), Rust ne permet pas l'utilisation d'une valeur plus d'une fois dans une même scope (ownership). Cela permet d'éviter des vulnérabilités double free.
Rust peut ainsi se permettre une gestion plus automatisée de la mémoire du fait de ces règles strictes et sûres. Il y a moins la place aux erreurs humaines dans le code final compilé, mais en échange il faut se plier à des règles pour que le code soit justement compilé. Quand le compilateur ne sait pas quoi faire de votre code, il faudra parfois l'expliciter (par exemple les annotations de lifetimes, mais c'est un sujet plus complexe).
Revenons à du code un peu plus simple :
fn main() {
let hello = "Hello world".to_string();
let first = first_word(hello);
println!("{} est le premier mot de {}", first, hello); // Problème !
}
fn first_word(word: String) -> &str {
// on pourrait faire plus simple avec split_whitespace()
// mais le but n'est pas de faire un concours de concision :)
let bytes = word.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &word[0..i];
}
}
&word[..]
}Ce code ne compilerait pas du fait de l'application de l'appartenance stricte d'une valeur à sa scope. hello a été donné à first_word(), et a en conséquence été supprimé automatiquement quand il est tombé de la scope de cette fonction. Donc on ne peut plus l'appeler après.
Il faudrait donc que fist_word() emprunte seulement :
fn main() {
...
let first = first_word(&hello);
...
}
// &str est préférable à &String mais ça marche aussi
fn first_word(word: &str) -> &str {
...
}Maintenant, ça marche ! Essayons de compiler ce code qui viserait à créer un dangling pointer :
fn main() {
let reference_sauvage = say_hello();
}
fn say_hello() -> &String {
let s = "Hello Ferris".to_string();
&s
}
Comme vous l'aurez deviné, ce code ne fonctionne pas non plus du fait des règles de Rust. Quand say_hello() se termine, s n'a plus de valeur, donc &s pointerait vers un espace de la mémoire invalide. Mais Rust nous coupe l'herbe sous le pied, le compilateur ne laissera pas passer.
Le code corrigé serait avec ici s qui sera donné à main() (pas optimisé et inutile, mais pour l'exemple) :
fn say_hello() -> String {
let s = "Hello Ferris".to_string();
s
}C'est peut-être évident, mais c'est un acquis du langage qui n'est pas forcément présent ailleurs…
Nous avons effleuré quelques concepts fondamentaux de Rust qui en font un langage sûr (et casse-bonbons au début, mais pour le bien de tous). Son adoption ne fait que croître, par exemple :
- Chez Microsoft qui a rejoint la fondation Rust récemment
- Ou encore Google qui l'adopte déjà pour des composantes d'Android 12
- Sa place dans Linux se rapproche bientôt d'une réalité
- Servo, moteur de rendu pour Firefox (jusqu'au délire de la direction)
C'est non-exhaustif, mais il y a un vrai mouvement en faveur de son adoption et je suis très optimiste quant à son avenir (je l'apprends moi-même donc je ne suis pas du tout biaisé 😃).
Cool, alors on bouge tous vers Rust ?
Comme dit, porter un code en C/C++ vers Rust peut s'avérer très complexe, car il faut parfois revoir toute la logique d'un code. De plus, considérez des langages de plus haut-niveau pour des composantes qui n'ont pas besoin des performances d'un langage bas-niveau, histoire de s'épargner de cette complexité qui n'est pas nécessaire.
Mais oui, faites comme les gens cool et apprenez le Rust !
Au niveau du système : comment s'en protéger ?
Ces vulnérabilités étant communes, de nombreux mécanismes de protection (que j'appellerai mitigations) ont vu le jour à différents niveaux :
- Compilateur (GCC, clang/LLVM, MVSC, etc.)
- Allocateur de mémoire (implémentations de malloc)
- Système (Linux, Windows, macOS, iOS, Android, etc.)
- Et même hardware !
Au niveau du compilateur (SSP)
Les compilateurs de code C/C++ implémentent un mécanisme de protection basique contre les stack-based overflow. Un de ces mécanismes repose sur l'utilisation de canaries : des morceaux de mémoire qui sont ajoutés de façon adjacente et dont la valeur peut être vérifiée, ce qui rend des overflow détectables du fait de la destruction de ces canaries le cas échéant.
C'est un peu le même concept qu'un warrant canary, si vous êtes davantage familiarisé avec ce concept. Tant qu'il y a le canary, c'est comme dire "an overflow has not been there".
- Dans GCC, ce mécanisme est appelé Stack Smashing Protector (SSP) et peut être utilisé lors de la compilation avec le paramètre
-fstack-protector-strong(sous sa forme actuelle). FORTIFY_SOURCEpermet également d'éviter des situations d'overflow notamment via l'usage de fonctions unsafe vues précédemment.- L'option
-fPIE(Position Independent Executable) est également importante pour permettre à l'application de bénéficier de ASLR que nous verrons plus bas.
Gentoo documente ces fonctionnalités. Il est fortement conseillé de compiler vos programmes avec cette forme de protection ; les paquets sous Arch Linux le sont tous par défaut par exemple.
Ces options sont valables pour GCC mais sont présentes sous d'autres noms et implémentations dans les autres compilateurs également. Il est intéressant de constater que Clang bénéficie d'autres mitigations modernes :
- Control-Flow Integrity : son rôle est aussi de protéger contre cette famille de vulnérabilités. CFI empêche précisément un attaquant de "convertir" le bug en exploit, dans le sens où un attaquant exploite le bug pour au final exécuter son code. CFI empêche cela en indiquant au moment de la compilation ce que le programme est censé faire. On pourrait traduire par "intégrité du flux d'exécution".
- Shadow stacks : une mitigation supplémentaire contre les stack-based buffer overflow. Elle fonctionne sur le principe de l'utilisation d'une seconde stack qui contient les adresses retournées par les fonctions d'un programme.
Nous en avons parlé à plusieurs reprises. CFI est par exemple adopté par Chromium, Windows (CFG), Android, et Google compile Linux avec CFI depuis 2018 pour ses Google Pixel.
Bien évidemment, ce serait aller un peu vite d'en finir simplement ici mais les compilateurs sont un sujet d'une complexité (que je ne maîtrise pas moi-même) telle qu'il vaut mieux ne pas trop s'étaler. Sachez simplement que ces protections-là sont plus ou moins efficaces, elles éliminent effectivement une partie des vulnérabilités en question.
Au niveau de l'allocateur de mémoire
Pour comprendre le pourquoi du comment, il faut d'abord savoir qu'une bibliothèque C/C++ est nécessaire pour interfacer un programme avec les API du système correspondant (les appels systèmes de Linux par exemple, mais c'est valable aussi pour Windows).
Parmi elles, une fonctionnalité est l'allocation dynamique de mémoire malloc (avec realloc, calloc, free, etc.) dans le tas (heap). Il se trouve que cette fonctionnalité peut être implémentée de différentes façons. Par défaut glibc ou musl (deux bibliothèques C/C++ populaires sur Linux) implémentent leur propre allocateur de mémoire, mas il est possible d'utiliser une autre implémentation de son choix.
 GrapheneOS
GrapheneOSVoici l'implémentation de GrapheneOS par exemple, qui est basée sur celle d'OpenBSD et améliorée, compatible avec Bionic (Android), glibc et musl. Je vous invite à lire son README.md qui explique en long et en large ses améliorations, qui concernent entre autres :
- Les canaries que nous avons mentionné plus haut (ceux-ci peuvent être bruteforce par exemple, il convient de les renforcer)
- Le zeroing (écriture de
0) de la mémoire après des petites allocations pour protéger contre quelques use-after-free
L'allocateur nouvelle génération de musl s'inspire d'ailleurs beaucoup des travaux de hardened_malloc, n'allant toutefois pas aussi loin dans les mesures de sécurité pour conserver une empreinte mémoire faible.
Liste non-exhaustive : il y a d'autres améliorations configurables pour atteindre le compromis sécurité/ressources/performances que vous souhaitez. L'objectif principal d'un allocateur renforcé est de prévenir des vulnérabilités liées au tas (heap).
C'est chouette, je peux l'installer ?
Oui, bien sûr ! Et c'est aussi simple qu'un coup de make pour compiler depuis les sources. Vous pouvez charger cet allocateur pour les applications que vous souhaitez avec la variable d'environnement LD_PRELOAD :
LD_PRELOAD="/usr/lib/libhardened_malloc.so" /usr/bin/firefoxC'est un exemple, par contre le plus drôle c'est que Firefox casse souvent avec Hardened Malloc. Mais la majorité des applications fonctionne plutôt bien. Quand il y a un problème de compatibilité, ce n'est pas Hardened Malloc le responsable, mais il est plutôt un symptôme d'un problème sous-jacent au niveau du programme et de sa gestion de la mémoire : il faudrait idéalement le signaler systématiquement aux développeurs du programme en question.
Personnellement, je l'utilise de plus en plus pour mes images OCI, par exemple Mastodon (il est commun d'utiliser jemalloc pour des applications Ruby, mais cet allocateur privilégie les performances à la sécurité).
### Build Hardened Malloc
ARG ALPINE_VERSION
FROM alpine:${ALPINE_VERSION} as build-malloc
ARG HARDENED_MALLOC_VERSION
RUN apk --no-cache add build-base git gnupg && cd /tmp \
&& wget -q https://github.com/thestinger.gpg && gpg --import thestinger.gpg \
&& git clone --depth 1 --branch ${HARDENED_MALLOC_VERSION} https://github.com/GrapheneOS/hardened_malloc \
&& cd hardened_malloc && git verify-tag $(git describe --tags) \
&& make
### Build Mastodon (production environment)
FROM node-ruby as mastodon
COPY --from=build-malloc /tmp/hardened_malloc/libhardened_malloc.so /usr/local/lib/
ENV LD_PRELOAD="/usr/local/lib/libhardened_malloc.so"J'apprécie cette façon de faire car chaque application réagit différemment, donc bon. Au passage, Whonix a un package pour Debian, et Arch Linux le propose dans AUR.
Pour ce que ça vaut, c'est-à-dire pas grand chose, je constate cependant que la consommation est un peu plus élevée (Mastodon en exemple) :

De l'ordre de 10-15% ici, c'est assez dur à estimer. De toute façon ce n'est pas la RAM qui manque pour moi, j'accepte largement ce compromis. Enfin, selon l'application, hardened_malloc s'avère parfois même plus efficace que l'allocateur de glibc ou encore jemalloc :

Gardez en tête que c'est application-dépendant et que hardened malloc est très agressif par défaut (des options peuvent être relâchées). Le sujet des allocateurs est lui-même trop complexe pour en faire des généralités.
Pour vérifier que vous utilisez bien hardened_malloc, c'est assez évident quand vous regardez dans /proc/self/maps, notamment toutes les régions isolées. Et vous voyez clairement que la lib en question est chargée dans l'espace mémoire (aussi vérifiable avec ldd).
Au niveau du système (ASLR)
ASLR est l'acronyme de Address Space Layout Randomization. Cette technique permet d'arranger aléatoirement la mémoire d'un programme (que ce soit la stack, heap, l'exécutable lui-même) de telle sorte à limiter la possibilité qu'une buffer overflow soit exploitée, car elle est d'autant plus facile partant du principe que des emplacements de mémoire sont prédéfinis.
Mais du coup c'est de la sécurité par l'obscurité, non ?
C'est… essentiellement ça ! Mais attention : la sécurité par l'obscurité n'est pas toujours une mauvaise chose malgré sa connotation négative ; c'est une mauvaise chose seulement quand elle représente votre seule couche de protection (ce qui n'est pas le cas ici).
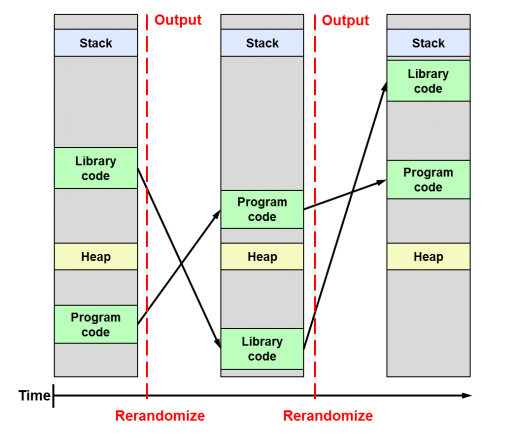
En pratique, il se trouve qu'ASLR est une mesure très efficace et indispensable, activée par défaut presque partout depuis son introduction par PaX en 2001, dans des formes plus ou moins efficaces et qui ont évolué ensuite :
- OpenBSD depuis 2003 : premier OS mainstream à l'implémenter
- Linux depuis 2005 (2.6.12)
- Windows depuis 2007 (Vista)
- OS X (macOS) depuis 2007 (Leopard 10.5)
- iOS depuis 2011 (4.3)
- Android depuis 2011 (ICS 4.0)
ASLR s'applique à l'userspace, mais également au kernel (KASLR). Dans les faits, sachez cependant que KASLR a un bénéfice questionnable.
Nous avons brièvement parlé d'ASLR pour Linux :

Pour Windows, nous y reviendrons peut-être plus en détails un jour. En attendant, vérifiez dans Exploit Protection que ces options sont activées :
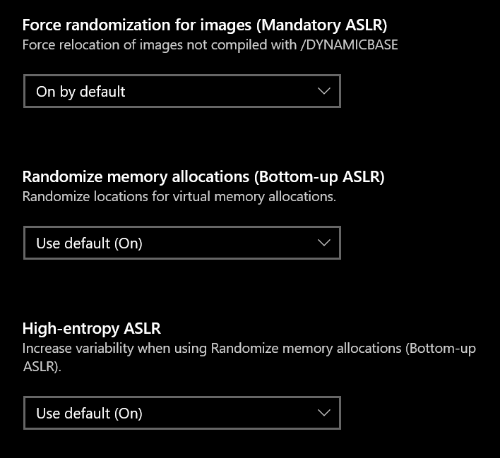
En particulier la première Mandatory ASLR qui n'est pas activée par défaut. Certaines vieilles applications vont peut-être casser, mais ce sont des applications que vous devriez ne pas utiliser en dehors d'une sandbox.
Au niveau du hardware (MTE)
MTE est l'acronyme de Memory Tagging Extension. C'est une fonctionnalité introduite dans ARMv8.5, une révision que Qualcomm (ou autre constructeur de SoC ARM) n'utilise pas encore mais probablement dans les années à venir. Google a déjà préparé son adoption dans Android :
Based on the current data points, MTE provides tremendous benefits at acceptable performance costs. We are considering MTE as a possible foundational requirement for certain tiers of Android devices.
MTE est donc une mitigation contre toute la famille de vulnérabilités abordée dans cet article, mais cette fois-ci au niveau du hardware ce qui promet donc une protection supplémentaire avec un surcoût plus faible ; car oui, ces protections ci-dessus ont un coût en performances et ressources. Pour ce faire, MTE ajoute 16 nouvelles instructions qui devront être utilisées par une couche de bas-niveau du système.
Comme son nom l'indique, chaque allocation de mémoire sera taguée, et son accès n'est possible que par un pointeur avec le tag correspondant.
Prenons ces exemples dont les explication sont fournies en détails par SEQRED mais que je vais tâcher de vulgariser :
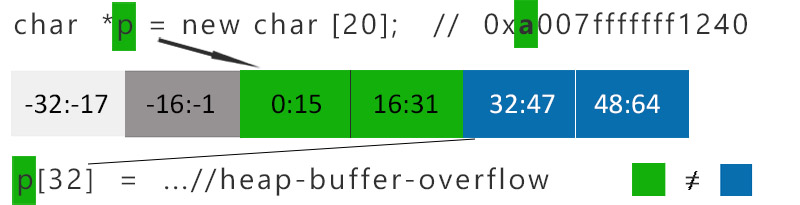
Quand le pointeur p est déréférencé à la position 32, il est pris en flagrant délit de heap-based buffer overflow. Les bits de tag (vert) ne correspondent pas à l'emplacement (bleu) !
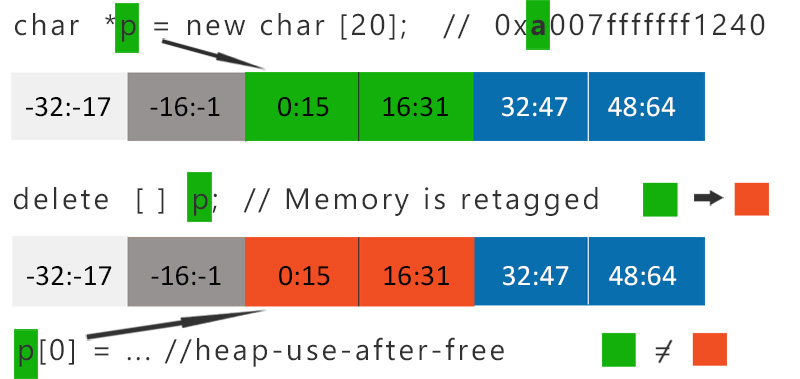
Lorsque la mémoire allouée en question ne l'est plus, il y a un mécanisme de retaggage (vert puis rouge) ; ce qui permet de détecter des use after free (vert n'est plus présent).
Cette détection est efficace et très performante par rapport aux méthodes purement software. Elle fera probablement son entrée dès 2022 sur les premiers appareils équipés de SoC armv9.
Conclusion
Phew, c'était une longue promenade, mais une promenade passionnante !
Les aficionados de la sécurité informatique n'auront sans doute rien appris de nouveau ici, mais si cela a donné les informations nécessaires à certaines personnes pour pouvoir mieux comprendre ces vulnérabilités, j'en serais très satisfait.
De plus cela m'évitera des redites à l'avenir, car nous avons déjà mentionné très souvent l'existence de ces vulnérabilités par le passé. Au moins, le tour est fait de surface. Nous avons également vu à quel point la sécurité moderne s'organise par couches de sécurité et l'importance d'avoir ces mitigations à disposition.
Évidemment, je n'ai pas mentionné des mitigations plus radicales comme le sandboxing, qui font parfaitement sens pour contenir tout type de vulnérabilité finalement. Chromium est par exemple intéressé pour passer autant de composantes non-sandboxées que possible dans des langages memory-safe, puis plus tard de s'attaquer aux composantes de la sandbox.
Quoiqu'il en soit, il est probable que les années à venir connaitront toujours des vagues de vulnérabilités critiques liées à la gestion de la mémoire, donc je ne peux qu'insister (une nouvelle fois) sur l'importance de maintenir à jour son système. Nous sommes cependant à l'aube de nouvelles techniques de protection excitantes telles que le memory tagging, et bien sûr l'émergence et l'adoption croissante de langages modernes comme Rust.