
gVisor & Kata : des sandbox pour renforcer l'isolation des conteneurs
Les conteneurs apportent sur le papier un environnement réplicable et léger avec un espace utilisateur isolé, loin de la lourdeur des machines virtuelles. En réalité, l'isolation est une problématique qui doit être considérée de plus près : nous verrons ici des solutions proposées...


Tout d'abord, je vais parler de ma relation avec les conteneurs. J'ai découvert Docker en 2015 (c'était hype) et depuis je ne m'en passe plus : j'ai beau ne pas être développeur, administrateur système, ou DevOps de métier, j'utilise les conteneurs pour mes projets personnels aussi bien que pour déployer des services personnels (à tout hasard, ce blog). C'est une relation amour-haine, mais je vais garder mes remarques pour une prochaine fois.
Je ne vais pas m'étaler sur la technologie des conteneurs elle-même, d'autres articles l'ont déjà fait en détails. Cependant, avant de rentrer dans le vif du sujet, certaines subtilités sont à mettre au clair afin que vous puissiez mieux comprendre de quoi il s'agit.
Contexte
La révolution des conteneurs
Quand on parle de conteneurs, on pense souvent automatiquement à Docker (à tort aujourd'hui ?). Mais c'est surtout parce que Docker a popularisé les conteneurs il y a quelques années, car désormais on entend parler également de Kubernetes et d'autres technologies similaires mais différentes.
Au départ, Docker utilisait LXC (Linux Containers). LXC est une des premières technologies de conteneurs, aujourd'hui embarquée dans le noyau Linux, qui a été rendue possible par l'inclusion des :
- cgroups : entre autres responsables de la limitation et l'isolation des ressources allouées à un conteneur : IO, réseau, mémoire, CPU, etc.
- namespaces : partitionnent les ressources propres au kernel : IDs, systèmes de fichiers, IPC (inter-process communication), etc.
Un "conteneur" Linux se distingue ainsi des chroot à l'ancienne...
Docker fournissait des outils de haut-niveau pour LXC, rendant la technologie accessible par une couche d'abstraction supplémentaire, histoire de résumer.
Puis Docker s'est émancipé, et en 2014 à l'occassion de sa version 0.9, libcontainer remplaça LXC : écrit majoritairement en Go, libcontainer se voulait être une couche d'abstraction supplémentaire permettant de travailler facilement avec différentes fonctionnalités de Linux (les cgroups, les MACs* comme AppArmor et SELinux, les interfaces réseau, iptables, etc.).
*MACs = mandatory access controls = politique de contrôle d'accès.
L'écosystème des conteneurs
libcontainer fut une première étape vers l'éclatement du projet monolithique qu'était Docker. Cet éclatement a eu lieu en 2016 :
- Aujourd'hui, Docker (ou Kubernetes, etc.) en tant que tel propose des outils de haut-niveau permettant de gérer des conteneurs facilement pour l'utilisateur final.
- Ce qu'on appelle "images Docker" sont en réalité des images qui suivent une spécification OCI (Open Container Initiative) : c'est donc devenu un standard qui peut être utilisé et implémenté par des technologies alternatives de gestion de conteneurs.
L'écosystème des conteneurs représente aujourd'hui bien plus que Docker, si certains d'entre vous n'étaient pas encore au courant ! Docker restera l'exemple utilisé au travers de cet article, car je l'utilise moi-même, mais ce qui sera dit sera grossièrement valable pour ses alternatives (en dehors de quelques subtilités dont on ne me tiendra pas rigueur).
Docker en 2021, c'est quoi ?
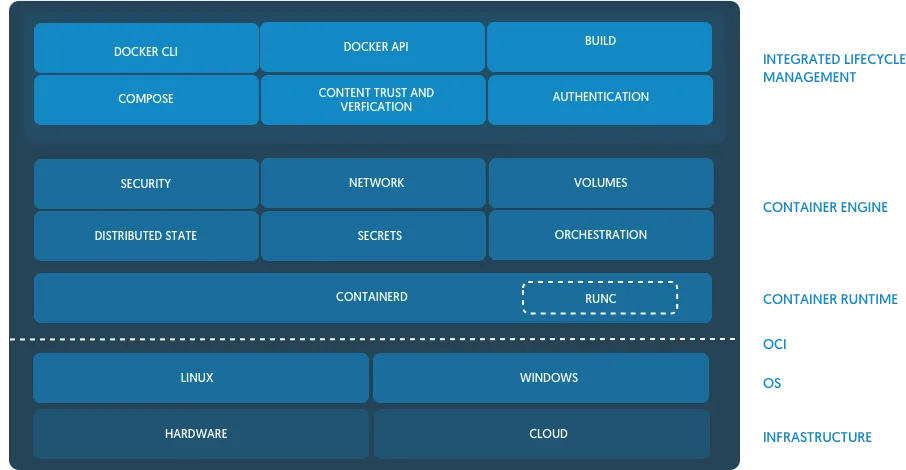
Docker fonctionne ainsi maintenant (gardez en tête que nous descendons du haut niveau au plus bas niveau) :
- Le daemon Docker communique avec le client (en CLI par exemple, avec les commandes
docker). Docker est en soit une couche de haut-niveau qui permet à l'utilisateur final de facilement gérer les ressources de ses conteneurs et de les orchestrer comme bon lui semble. - Puis Docker communique ensuite avec le daemon containerd, une couche de plus bas niveau : c'est en quelque sorte la pierre angulaire à l'interfaçage avec le standard OCI. Il gère le cycle de vie de nos conteneurs. CRI-O est l'alternative à containerd utilisée par Kubernetes.
- En effet, containerd va à son tour communiquer avec les containers runtimes proprement dit, qui suivent donc ce standard OCI. Ces OCI runtimes vont donc être responsables de la création et du bon fonctionnement de vos conteneurs. runc est celui utilisé par défaut dans Docker (runc absorbe libcontainer dont nous avions parlé).
Oh, et le saviez-vous ?
- Vous pouvez tout à fait utiliser containerd et vous passer de Docker. Ce sont des couches de haut-niveau que l'utilisateur final peut choisir d'utiliser ou non. Vous pouvez même utiliser directement runc !
- J'ai omis un élément final dans la chaîne, les containerd-shim qui sont des processus légers parents aux runtimes de conteneurs, leur permettant ainsi de ne plus dépendre d'un daemon pour leur fonctionnement.
Encore une fois, d'autres articles vous détailleront davantage le fonctionnement de Docker ou autre "runtime de haut-niveau" comme Kubernetes ou Podman. Tout ce qu'il faut réellement retenir ici, c'est cette histoire d'OCI qui permet d'avoir des conteneurs standardisés et interopérables. Et ça, c'est génial.
OCI runtimes
runc (anciennement libcontainer) est donc l'implémentation de référence OCI. C'est le runtime de bas-niveau qui va gérer la création et le fonctionnement de nos conteneurs, et qui implémente toutes les fonctionnalités de Linux permettant de gérer les ressources et la sécurité de ces derniers :
- Les namespaces, dont les user namespaces
- Les cgroups, évidemment ! Pour la limitation et l'isolation des ressources (CPU, RAM, IO, réseau, etc.)
- Des mesures de sécurité : MACs (AppArmor, SELinux), seccomp, etc.
C'est non-exhaustif, mais vous avez compris ! L'OCI étant un standard, chacun est libre de développer sa propre implémentation. En voici des exemples :
- Kata Containers (par OpenStack)
- gVisor (par Google)
- Nabla Containers (par IBM)
- Firecracker via Ignite/Kata (par Amazon)
Cet article s'intéressera aux deux premiers, Kata et gVisor. Non pas que les autres sont inintéressants, mais ces deux-là proposent une approche radicalement différente. Mais avant de les détailler, regardons ce que ces alternatives tentent de résoudre...
Conteneurs et sécurité : allô ?
Les conteneurs tels qu'ils ont été popularisés n'ont pas été pensés particulièrement pour la sécurité. Ils ont été davantage perçus comme des outils de développement plutôt que des moyens de mise en production, où la sécurité devient critique.
Je ne m'adresserai pas dans cet article aux failles de l'écosystème des conteneurs, d'autres l'ont fait. Je m'intéresserai à l'isolation proprement dite d'un conteneur vis-à-vis de l'hôte.
Les conteneurs proposent par leur nature une isolation de l'userpace, et les runtimes implémentent de nos jours des mécanismes pour limiter les appels systèmes dangereux (seccomp), mais est-ce suffisant ?
CVE-2019-5736 : s'échapper d'un conteneur
Plutôt que de mettre en garde sur les dangers, cette fois-ci nous tenons un bel exemple. Cette CVE est une vulnérabilité de runc qui permettait à un attaquant de s'échapper du conteneur (ceci en modifiant directement le comportement de runc au travers de cette vulnérabilité) et, finalement, de prendre le contrôle total de l'hôte. Game over!

Oui, s'échapper d'un conteneur, c'est possible et ça pourrait demander quelques manipulations seulement !
Mitigations
Par défaut (en tous cas chez Docker), un conteneur utilise des processus root. Mais quand on dit root dans un conteneur, c'est en réalité aussi le root de l'hôte. On comprend vite le problème et sa solution : si un attaquant s'échappe du conteneur, il est effectivement root sur l'hôte, le pire qui puisse arriver.
Les solutions sont multiples et complémentaires :
- De nombreuses images
DockerOCI permettent de fonctionner rootless. Soit par dégradation des privilèges (gosu), soit avec la directiveUSERdans un Dockerfile qui indique à Docker d'utiliser cet utilisateur plutôt que root. - Si l'image ne propose ni l'un ni l'autre, il est possible de fournir au runtime un paramètre (
--useren Docker CLI) pour lui indiquer d'utiliser cet utilisateur plutôt que root par défaut. - Quand ces mesures sont mises en place, vous devriez préciser
--security-opt=no-new-privilegesau runtime pour bloquer des tentatives d'escalation de privilèges au sein-même du conteneur. - Enfin, les user namespaces. Cette fonctionnalité de Linux constitue un rôle important dans l'isolation que peut fournir runc : le root dans le conteneur ne sera pas le root sur l'hôte.
- La mise en place d'une politique de contrôle d'accès (Docker fournit un profil AppArmor par défaut) ainsi que du filtrage d'appels systèmes (Docker configure par défaut seccomp à cet effet).
Ces solutions ne s'excluent pas, elles sont à utiliser ensemble avec d'autres bonnes pratiques : par exemple, veiller à qui accède au socket Docker.
Il y a "conteneur" et "conteneur"
runc reflète la vision "classique" du conteneur simple, léger et performant, avec une isolation appréciée de l'espace utilisateur.
runc tire également profit des fonctionnalités de Linux pour renforcer sa sécurité comme je l'ai répété maintes fois plus haut, mais cela a ses limites, puisque Linux constitue lui-même une surface d'attaque majeure.

Un exemple de vulnérabilité "classique" et pourtant très critique. La CVE-2020-14386 peut être perçue comme un moyen d'échapper du conteneur avec tous les privilèges, avec en cause la surface d'attaque exposée par Linux.
C'est un problème qui n'est pas unique à Linux : Microsoft s'en préoccupe également et définit plusieurs niveaux d'isolation pour ses conteneurs.
Si bien que finalement, peut-on dire que la frontière entre conteneurs et machine virtuelle s'amincit ?
Il est question de trouver le meilleur compromis entre performances, simplicité, empreinte mémoire et isolation.
Kata Containers : la chimère conteneurs/VM
Nous l'avons vu plus haut, Kata Containers est une implémentation alternative du standard OCI. C'est un remplaçant drop-in de runc, lancé en 2017 et capitalisant sur l'initiative Intel Clear Containers.

Son approche : une machine virtuelle légère
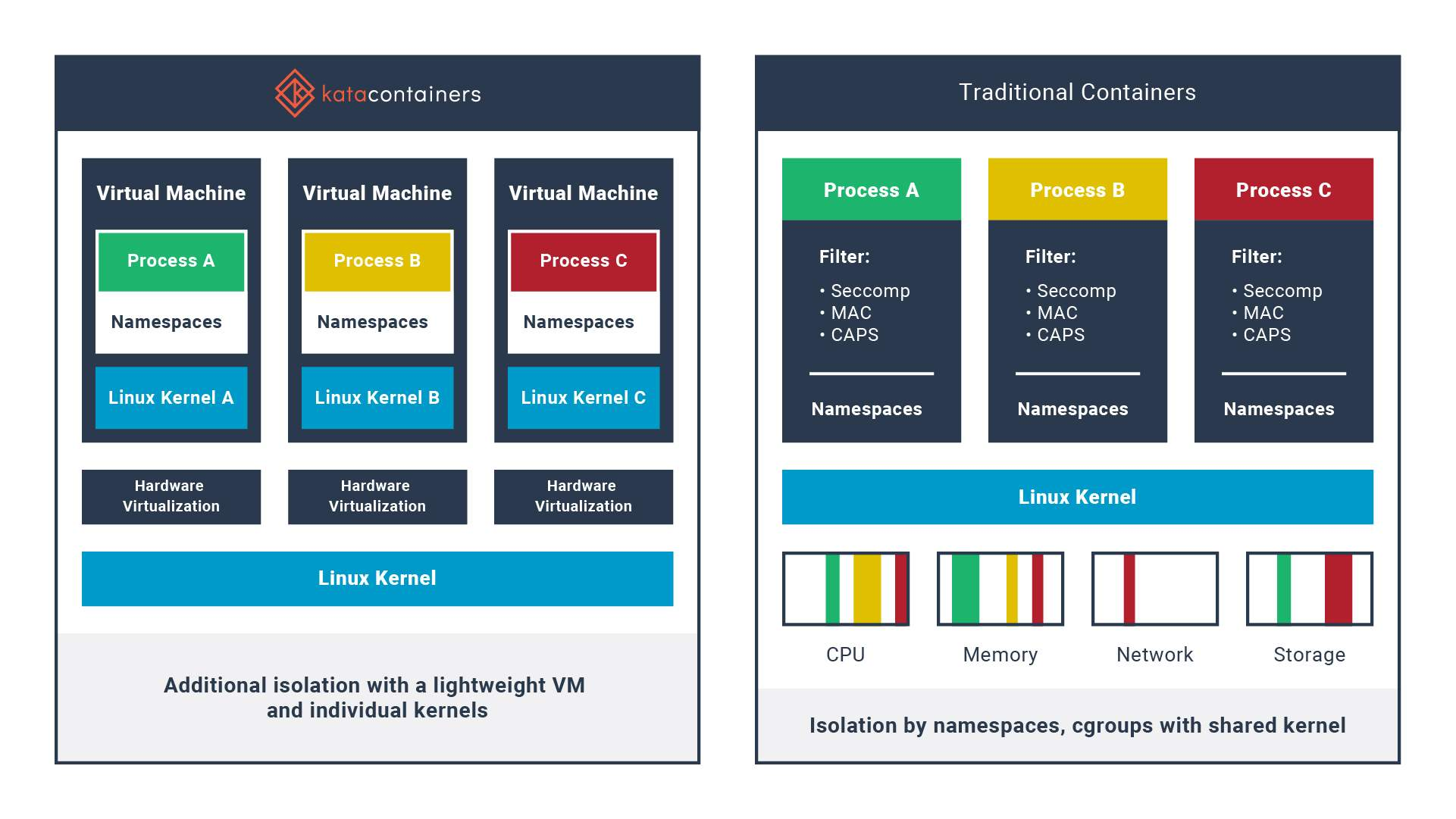
Pour renforcer l'isolation des conteneurs, Kata propose d'utiliser des VM légères qui embarquent leur propre noyau pour y loger vos conteneurs.
La simplicité du conteneur + la sécurité d'une machine virtuelle
Je pense qu'il n'y a rien d'autre à rajouter ! Vous pouvez gérer vos conteneurs comme avant, avec tous leurs avantages liés à leur gestion, mais en pratique ce seront des véritables petites machines virtuelles gérées par un hyperviseur qui dépassent les limitations de runc.
Forcément, cette isolation "classique" fournie par une machine virtuelle n'est pas une grande nouveauté en soi. De plus, on rappelle qu'elle repose toujours sur la sécurité de l'hôte qui héberge l'hyperviseur, et ne vous exempt pas de faire attention à la sécurité proprement dite de vos applications.
Cette solution vient donc avec les défauts inhérents aux VM qui sont des performances moindres, une empreinte mémoire plus grande, et une lourdeur qui se fait ressentir au temps de démarrage du conteneur. Cependant, Kata fait de nombreux efforts d'optimisation pour réduire ce coût.
Pour ce faire, Kata repose sur QEMU-lite qui se distingue de la virtualisation traditionnelle par sa légèreté : en savoir plus ici.
Installation & configuration (Docker)
J'aime bien écrire, mais j'aime autant tester des choses pour voir comment mettre en pratique ces mesures de sécurité dans notre quotidien. J'ai donc procédé à installer Kata Runtime sur mon serveur qui utilise Debian Buster comme OS ainsi que le kernel stable des backports.
 kata-containers
kata-containers
Malheureusement, j'ai dû passer par Snap pour des raisons de simplicité. Je n'en suis pas un grand fan, mais bon, j'ai fait une exception.
Enfin, rappellez-vous : Kata est un runtime OCI-compliant. Docker supporte tout à fait l'utilisation de plusieurs runtimes. Il suffira donc d'ajouter à /etc/docker/daemon.json les lignes suivantes :
{
"runtimes": {
"kata": {
"path": "/snap/bin/kata-containers.runtime"
}
}
}Enfin, on redémarre le daemon Docker avec service docker restart et on peut confirmer que le runtime est bien reconnu avec docker info :
Runtimes: io.containerd.runtime.v1.linux kata runc runsc io.containerd.runc.v2Pour la configuration de Kata proprement dite, vous devriez avoir une commande kata-containers.runtime. Le fichier de configuration se situe dans /etc/kata-containers/configuration.toml : pas de panique, par défaut, tout fonctionne. Modifiez-le selon vos besoins, par exemple, pour les ressources allouées minimales.
Utilisation et limitations
A mon avis, c'est là que la magie de l'interopérabilité est géniale. Kata étant un runtime OCI, vous n'avez pas vraiment à configurer autre chose...
Par défaut, Docker utilise toujours runc (bien que ce soit modifiable). Il est tout à fait possible de dire à Docker d'utiliser un runtime alternatif au moment de créer un nouveau conteneur :
~$ docker run -ti --rm --runtime kata alpine sh
/ #Aussi simple que ça, et il y a bien évidemment l'équivalent docker-compose avec la clé runtime. Maintenant amusons-nous un peu :
/ # uname -r
5.4.60.containerComme prévu, ce conteneur sera tout comme une vraie machine virtuelle. Ce kernel n'est pas celui que j'utilise sur l'hôte (5.10.x).
/ # ping -c 5 alpinelinux.org
PING alpinelinux.org (147.75.101.119): 56 data bytes
64 bytes from 147.75.101.119: seq=0 ttl=57 time=25.893 ms
64 bytes from 147.75.101.119: seq=1 ttl=57 time=25.860 ms
64 bytes from 147.75.101.119: seq=2 ttl=57 time=26.369 ms
64 bytes from 147.75.101.119: seq=3 ttl=57 time=25.865 ms
64 bytes from 147.75.101.119: seq=4 ttl=57 time=25.940 ms
--- alpinelinux.org ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max = 25.860/25.985/26.369 msAucun souci pour la résolution DNS et la connectivité en général. Ici, je n'ai pas précisé de réseau, donc par défaut mon conteneur est sur le réseau bridge par défaut de Docker.
En pratique, on utilise aujourd'hui des user-defined bridge pour gérer la connectivité entre les conteneurs. Après des essais :
- La connectivité entre des conteneurs de différents runtimes fonctionne
- Mais... quand un conteneur n'utilise pas la stack réseau de l'hôte (Kata/gVisor), il ne peut pas utiliser la résolution DNS Docker. Donc il faudra fournir un
resolv.confet utiliser des IP statiques.
/ # grep -c processor /proc/cpuinfo
2La configuration par défaut alloue deux cœurs virtuels à chaque machine virtuelle. Vous pouvez le modifier dans la configuration de Kata.
Quand on précise un nombre de cœurs à utiliser via Docker, Kata ne les voit que comme du "surplus" :
~$ docker run -ti --rm --runtime kata --cpus 2 alpine grep -c processor /proc/cpuinfo
4Il en va de même pour la RAM. Par défaut, vous aurez 2GB de RAM par machine virtuelle, et vous pouvez préciser un "surplus" avec --memory. C'est un comportement assez étrange dans leur implémentation de la spec cgroups, mais on peut se débrouiller ainsi, je suppose...
D'autres limitations sont documentées ici :
kata-containersgVisor : l'innovation de Google

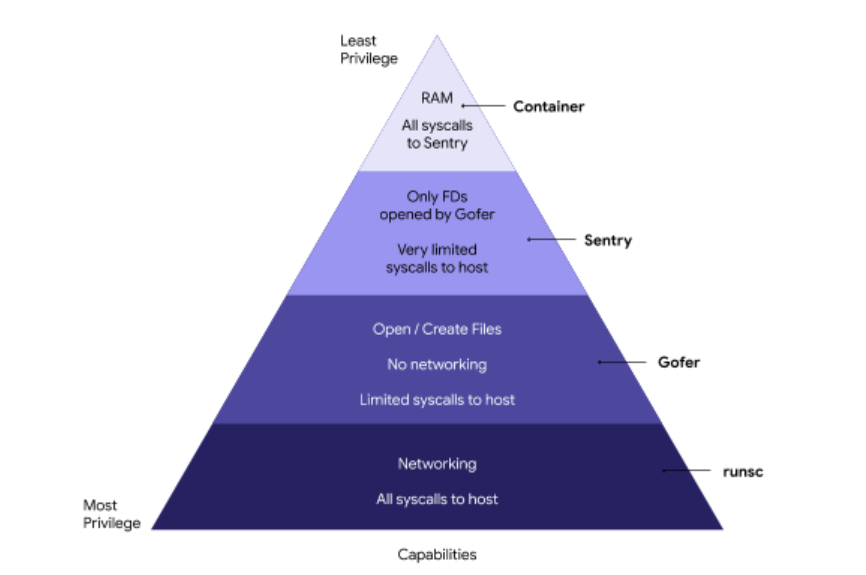
gVisor est une autre approche qui vise à renforcer l'isolation des conteneurs sans pour autant perdre ce qui fait leur légèreté en cédant à des VM. gVisor est un projet qui est constitué de :
- Sentry : un noyau simple écrit en Go qui fonctionne dans l'espace utilisateur, et aura pour rôle d'intercepter et de répondre à des appels système de l'application. Chaque application a sa propre instance de Sentry, qui a une communication très restreinte avec le noyau hôte.
- Goofer : écrit en Go, ce processus sera entre autres le médiateur entre Sentry et le système de fichiers sur l'hôte, comme Sentry est restreint par seccomp sans accès à ce dernier. Chaque application a aussi sa propre instance de Goofer, le bras droit de Sentry.
- runsc : le point d'entrée pour utiliser gVisor avec l'écosystème OCI, et qui permet de considérer gVisor comme un remplaçant drop-in de runc.
Rappelons que Go a l'avantage d'être un langage memory-safe qui par nature est protégé de nombreuses attaques liées à la mémoire.
Son approche : un kernel dans l'userspace ?
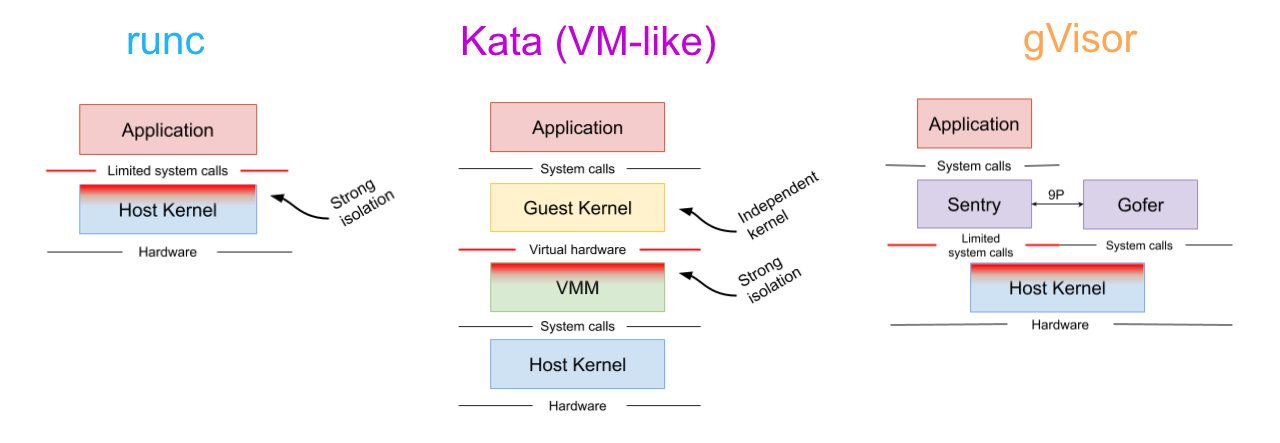
gVisor cherche à rajouter une couche d'isolation supplémentaire pour protéger l'hôte, sans la lourdeur d'une VM entière, et là où runc repose sur quelques fonctionnalités (seccomp-bpf) pour filtrer les syscalls. Mais ici, au lieu de simplement filtrer puis de les passer au kernel hôte, gVisor a l'ambition d'aller jusqu'à les satisfaire en les réimplémentant dans Sentry, un kernel écrit en Go qui tourne comme une application dans l'espace utilisateur.
La légèreté d'un conteneur + la "sécurité" d'une machine virtuelle
Avec gVisor, aucun appel système n'est passé directement à l'hôte, réduisant drastiquement la surface d'attaque originalement présente.
Pour intercepter les appels systèmes, gVisor nécessite une plateforme telle que ptrace ou KVM. Par défaut, gVisor utilise ptrace et fonctionne dans des environnements aussi bien baremetal que virtualisés, au prix de performances moindres. Il est possible d'utiliser KVM pour un overhead plus faible, mais sa disponibilité n'est pas garantie dans un environnement virtualisé contrairement à ptrace qui reste un choix par défaut évident.
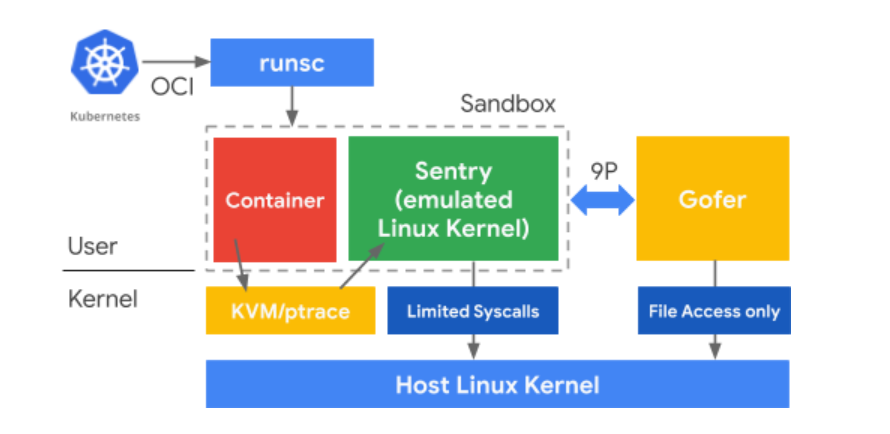
Sentry implémente donc partiellement les appels systèmes (plus de 70%), et communique de façon restreinte avec le kernel de l'hôte (moins de 10% des syscalls de ce dernier sont utilisés au total). C'est donc là sa force mais aussi sa faiblesse : pour le moment, gVisor ne fonctionne pas avec toutes les applications Linux.
Ainsi, gVisor suit plusieurs principes de la sécurité Zero Trust :
- Défense en profondeur : chacune des composantes entre elles accorde une confiance minimale
- Moindre privilège : chaque composante a les permissions minimales nécessaires à son fonctionnement
- Réduction de la surface d'attaque : limite la surface d'attaque de l'hôte exposée à la sandbox
- Sécurisé par défaut : la configuration par défaut doit être considérée comme sûre
gVisor n'a donc pas été vulnérable à la CVE-2020-14386 discutée précédemment.
Bien que Go soit suffisamment rapide pour "émuler" Linux dans l'espace utilisateur et ainsi ne pas exposer une surface colossale en C de l'hôte, les performances attendues doivent être relativisées.
Installation & exploration (Docker)
gVisor ne fait pas exception, je me dois de l'essayer ! Je suis personnellement fan de ce projet dont j'ai découvert l'existence l'année dernière, et bien qu'il ne soit pas totalement à maturité, il est déjà utilisé par Google en production.
Pour l'installer sur Debian, très simple :
curl -fsSL https://gvisor.dev/archive.key | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64,arm64] https://storage.googleapis.com/gvisor/releases release main"
sudo apt update && sudo apt install runscComme d'habitude, référez-vous à la page d'installation officielle.
Tout comme Kata, Docker le reconnaitra comme un runtime OCI alternatif une fois qu'il sera ajouté dans daemon.json :
{
"runtimes": {
"runsc": {
"path": "/usr/local/bin/runsc"
}
}
}On vérifie avec docker info :
Runtimes: io.containerd.runtime.v1.linux kata runc runsc io.containerd.runc.v2Parfait ! Maintenant, lançons un conteneur avec gVisor et vérifions la version du noyau :
~$ docker run -ti --rm --runtime runsc alpine uname -r
4.4.0Pourquoi 4.4.0 ? En fait, Sentry cherche à imiter l'environnement proposé par un noyau Linux 4.4.0, donc c'est plutôt logique.
/ # grep -c processor /proc/cpuinfo
12
/ # cat /proc/meminfo
MemTotal: 2097152 kB
MemFree: 2094064 kB
MemAvailable: 2094064 kBIl semblerait que par défaut, tous les cœurs sont alloués (on n'est pas vraiment dans le paradigme vCPUs des VM), et le conteneur ne voit "que" 2GB de RAM. Pourtant je n'ai rien limité... donc, gVisor est-il limité à 2GB ?
En fait, c'est ce qu'on pourrait croire. Il semblerait que gVisor utilise bel et bien l'ensemble de la mémoire disponible, mais cache l'information au sein du conteneur comme c'est une information sensible de l'hôte. gVisor respecterait a priori la spec cgroups comme runc. Certaines applications (minoritaires) reposent sur cette information pour adapter leurs ressources, ce qui peut causer des pépins.
On notera que dans un réseau user-defined bridge, on rencontre le même soucis qu'avec Kata : il faut utiliser un resolv.conf, ainsi que des IP statiques. Cela vient du fait que Sentry a sa propre stack réseau, netstack.
Pour ce dernier problème, gVisor permet de passer directement par la stack réseau de l'hôte en le configurant ainsi dans daemon.json:
{
"runtimes": {
"runsc-nethost": {
"path": "/usr/local/bin/runsc",
"runtimeArgs": [
"--network=host"
]
},
"runsc-kvm": {
"path": "/usr/bin/runsc",
"runtimeArgs": [
"--platform=kvm"
]
}
}
}Vous remarquerez que j'ai nommé ce runtime "runsc-nethost", il est tout à fait possible de faire coexister plusieurs configurations. Vous pouvez aussi configurer un "runsc-kvm" pour utiliser le backend KVM plus performant.
Ce n'est pas sans défaut, car si vous passez par la stack réseau de l'hôte, la surface d'attaque s'aggrandit en conséquence : à vous de trouver le compromis.
Il est à noter que tout comme Kata, gVisor n'est pas vraiment compatible avec la fonctionnalité user namespaces telle qu'implémentée dans Docker. Mais en réalité, ni l'un ni l'autre n'en ont besoin puisqu'elles implémentent leur propre namespace.
runsc always runs the container inside a user namespace that is isolated from the host. The user namespace exists only inside the sandbox and has no connection to the host. Therefore, there is no need to use userns-remap to isolate containers from the host.Conclusion
gVisor et Kata sont donc de véritables sandbox complètes, aux moyens différents mais aux mêmes objectifs, qui réduisent drastiquement la surface d'attaque par rapport aux approches classiques de conteneurs.
C'est une étape supplémentaire vers le modèle Zero Trust, car ici vous ne faites pas confiance à la sécurité du noyau de l'hôte.

Pour autant, bien que ce sont des remplaçants drop-in de runc, ce ne sont pas des solutions que vous devez appliquer en fermant les yeux :
- Kata est une solution assez lourde en ressources.
- gVisor n'implémente pas tous les syscalls, donc certaines applications sont incompatibles. Voir ici la liste des syscalls implémentés et des applications testées. Soyez prêts à debug !
J'ai présenté les 2 solutions car à mon avis elles peuvent se complémenter : gVisor quand l'application est compatible, sinon Kata en fallback. Vous pouvez bénéficier ainsi d'une isolation forte pour chacune de vos applications.
Je n'ai pas vraiment abordé le sujet, mais si les performances sont cruciales pour vous, voici quelques mesures de performance :
- Performance Guide - gVisor
- I/O performance of Kata containers (stackhpc.com)
- kata-containers-and-gvisor-a-quantitave-comparison (vexxhost.net)
A prendre avec des pincettes comme ces projets évoluent vite. D'ailleurs sur ma machine de test, les conteneurs Kata se lançaient instantanément !
Toujours est-il que ces solutions sont un peu bleeding edge sur les bords, et ne vous offriront pas des performances baremetal. Si ce n'est pas envisageable pour vous pour le moment, alors restez sur runc mais n'oubliez pas de le configurer convenablement en activant les user namespaces pour commencer. De plus, veillez à ce que votre installation utilise bien un profil AppArmor ainsi que seccomp. La sécurité de Docker par défaut a considérablement été renforcée malgré tout ces dernières années, assez que pour certaines critiques soient devenues plus ou moins obsolètes.
Comme je suis un peu fou, j'utilise gVisor et Kata depuis peu sur mon serveur personnel. Ce blog ainsi que son reverse proxy (Traefik) tournent avec gVisor. J'utilise Kata actuellement pour y mettre ma seedbox. Au passage excusez-moi si vous constatez des downtimes, je joue pas mal avec les conteneurs en ce moment pour moderniser ma stack.
En tous cas j'espère que certains découvriront ces projets fascinants, j'en vois très peu en parler. Je suis moi-même continuellement en approfondissement sur ces projets mais je manque de personnes avec qui en discuter. Je le répète, je trouve que gVisor est un projet démentiel qui mérite qu'on en parle davantage, et j'ai hâte de voir son évolution.
Voilà, je vais m'arrêter là pour cet article, mais je suis loin d'avoir terminé mon épopée avec les conteneurs... à bientôt !